
近日特斯拉人工智能团队副总裁 Ashok Elluswamy 在国际计算机视觉大会(ICCV)上发表了一场主题围绕特斯拉在自动驾驶领域的最新进展与核心理念的线上演讲。 同时也揭示了特斯拉如何通过端到端(End-to-End)神经网络架构,并以数据规模与神经仿真为核心,推动现实世界自动驾驶的智能化。

端到端学习:让汽车从感知到决策都由AI完成
目录
特斯拉的自动驾驶系统(FSD, Full Self-Driving)以端到端神经网络为基础,直接从车辆的多个摄像头输入影像,结合车速、导航地图、声音讯号与动态感测数据,生成车辆的控制命令,如转向与加速。 这与多数竞争对手的「模块化自驾架构」形成鲜明对比。 后者通常依赖大量传感器,并将系统拆分为感知(Perception)、预测(Prediction)与规划(Planning)三个部分。 虽然此方法在初期开发上较易管理,但当面对现实世界的复杂情境时,其缺乏整体优化能力,难以达成人类驾驶般的直觉判断。
特斯拉主张,端到端架构的关键优势包括:
他也举了一些案例:
案例一:水洼与对向车道的抉择
在一段视频中,AI 必须选择是否绕过前方大水洼,即便这意味着暂时偏离至对向车道。 传统规则会禁止这样的行为,但在该场景中,道路空旷、视野良好,AI正确判断没有迎面车辆,因而选择安全绕行。
案例二:理解动物意图
另外两段视频展示了AI如何区分两种场景:一群鸡正在过马路与一群鹅只是停留路旁。 传统模块化系统需定义复杂的行为分类与规划逻辑,而端到端模型则通过潜在变量(latent representation)自然捕捉这类意图。 结果是,AI在无明确规则的情况下,学会了「理解」动物行为的差异。
克服端到端学习的挑战
维度诅咒与数据洪流
现实世界的驾驶环境极为复杂,当车辆在路上行驶时特斯拉的自驾系统必须同时处理:
这些数据相当于约20亿个输入「token」,而 AI 最终必须将之压缩成两个输出:转向角与加速度。 要从中学习真实因果关系、避免虚假相关,是一项极具挑战的任务。 所幸,特斯拉拥有全球最大的实车数据库:每天约等同于一般人500年驾驶经验的数据量。 通过高效的资料引擎,特斯拉能从海量数据中挑选最具多样性与价值的片段,用于训练AI,提升对罕见情境的泛化能力。
如果使用这类 corner cases 数据进行训练,就会获得各种极端情况数据的解法。 以下是人工智能模型如何学习主动避免可能发生的冲突的一个范例。 令人印象深刻的是,人工智能在 5 秒左右做出反应,而情况可能升级为碰撞还很不明显。 人工智能需要了解外面下着毛毛雨,领头车可能正在打滑,它可能会撞到障碍物,然后弹回自我车辆的路径上,因此现在刹车是谨慎的。 只有非常有能力的人工智能系统才能提前预测这些可能发生的状况。
可解释性与安全验证
端到端模型虽强大,但其黑箱特性也引发可解释性与安全性疑虑。 特斯拉因此开发了可输出中间语义标记的架构,让AI在运作时能生成具意义的中间推理token,以便监控与调试。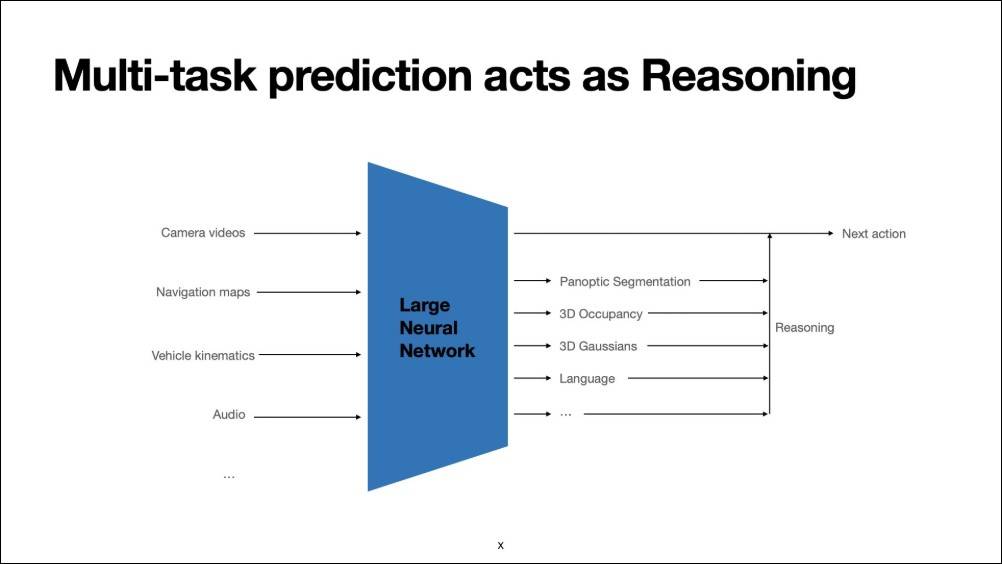
其中一项代表性技术是生成式高斯点云(Generative Gaussian Splatting)。 传统3D高斯重建需仰赖宽基线摄影视角,且计算耗时; 但特斯拉的生成式方法仅用车载镜头即可在约220毫秒内完成高质量3D重建,无需初始化,能同时处理动态物体,并与主AI模型联合训练。
此技术能以新视角重建环境,甚至生成语义丰富的自然语言推理,此类模型的轻量版本已运行于FSD v14.x版本之中。
评估与模拟:打造「神经世界」
训练再多数据仍不够,因为模型在开放式预测上的低损失,并不必然意味现实表现优异。 为解决这一难题,特斯拉开发了神经世界模拟器(Neural World Simulator):一个能以封闭循环方式测试AI决策的虚拟环境。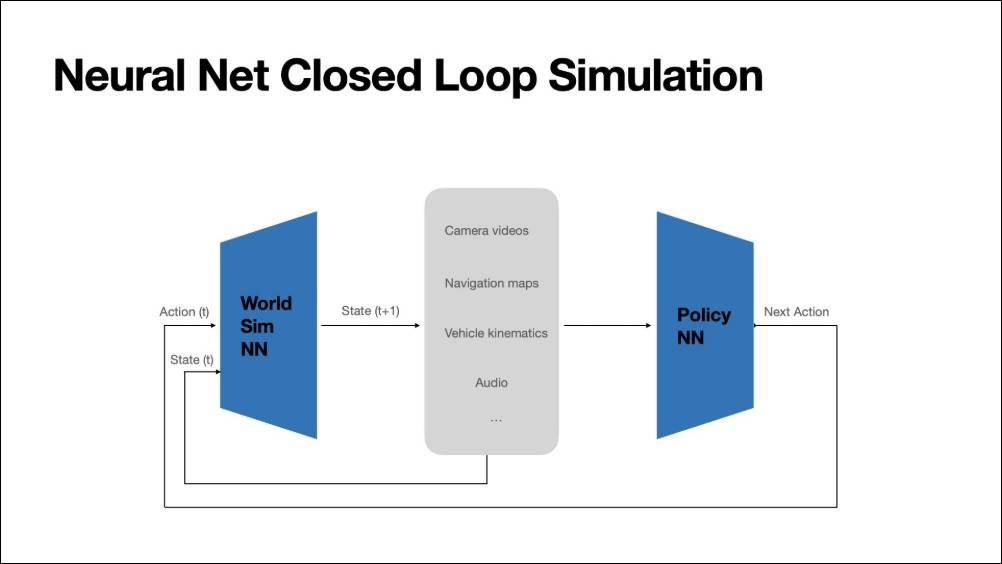
这个模拟器由特斯拉训练,但其任务是根据当前状态与动作,预测未来世界状态。 它能生成高分辨率、多镜头的影像序列,并对驾驶政策模型的指令做出实时反应。 (下面的视频不是实拍,而是特斯拉的神经世界模拟模型生成)
模拟器不仅能重现真实驾驶历史,也能产生对抗性场景(Adversarial Scenarios),用以测试AI在极端条件下的表现。
通过调整计算资源,模拟器能实时生成八个镜头、每秒24帧的完整驾驶画面,让人类驾驶者在虚拟世界中「实测」AI行为(以下画面是模拟器实时生成且真的可以驾驶)。
跨界应用:从自驾车到人形机器人
特斯拉强调,这些技术突破不仅服务于自动驾驶,更是通用机器智能(AGI)的基础。 相同的神经世界模拟与视觉生成模型,现已延伸至人形机器人Optimus。
在特斯拉超级工厂内,Optimus利用这套神经模拟环境学习导航与作任务。 视频显示,不同机器人动作在模拟中被准确反映,显示出端到端模型与模拟器的高度一致性。 这意味着,特斯拉正逐步构建一个车辆与机器人共享的智能体平台。
更进一步,这样的模拟系统可用于大规模强化学习(Reinforcement Learning),让AI在封闭环中无限迭代、超越人类表现,迈向「超人级驾驶与行动智能」。
 微信扫一扫
微信扫一扫