
AMD回应NVIDIA的H100 TensorRT-LLM结果,再次显示MI300X GPU使用优化的AI软件堆叠效能提升30%
AMD对NVIDIA的H100 TensorRT-LLM数据做出回应,MI300X在运行优化时再次在AI测试中处于领先地位软件。
两天前NVIDIA发布了其Hopper H100 GPU的新测试以展示他们的芯片性能比AMD展示的要好得多,在推进人工智能期间AMD将其全新的Instinct MI300X GPU 与Hopper H100芯片进行了比较,后者已经推出一年多了,但仍然是人工智能行业最受欢迎的选择。 AMD使用的测试并未使用TensorRT-LLM等优化库,而TensorRT-LLM为NVIDIA的AI芯片提供了巨大的提升。

使用TensorRT-LLM使Hopper H100 GPU的性能比AMD的Instinct MI300X GPU提高了近50%。 现在AMD正全力反击NVIDIA,展示MI300X如何在Hopper H100 运行其优化的软件堆叠时仍然保持比H100更快的效能。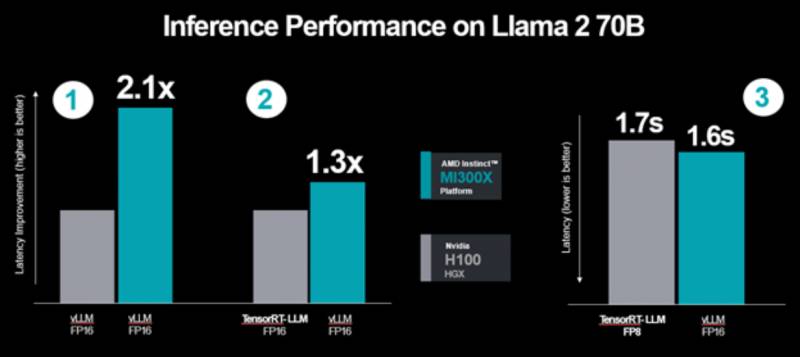
- 在H100上使用TensorRT-LLM,而不是AMD测试中使用的vLLM
- AMD Instinct MI300X GPU上的FP16数据型别与H100上的FP8数据类型的性能比较
- 将AMD发布的性能数据从相对延迟数转换为绝对吞吐量
因此AMD决定进行更公平的比较,根据最新数据我们发现在vLLM上运行的Instinct MI300X比在TensorRT-LLM上运行的Hopper H100性能提高了30%。
当然这些来回的数字有些出乎意料,但考虑到人工智能对于AMD、NVIDIA和Intel等公司的重要性,我们可以期待看到更多这样的例子被分享未来。 就连Intel最近也表示整个产业都在积极推动终结NVIDIA CUDA在产业中的主导地位。 目前的事实是英伟达在人工智能领域拥有多年的软件专业知识,虽然Instinct MI300X提供了一些可怕的规格,但它很快就会与更快的Hopper解决方案展开竞争。
赞 (0)
打赏
 微信扫一扫
微信扫一扫
微信扫一扫