
NVIDIA
NVIDIA AI平台为大型语言模型NeMo Megatron框架带来30%训练速度提升
SINCHEN·146 VIEWS 0 0


大型语言模型(large language model; LLM) 的规模和复杂性日益增加,NVIDIA宣布推出NeMo Megatron框架的更新内容,更新后可加快训练速度达30%。 这些更新内容包括两项开创性技术及一项超参数工具,用在任意GPU数量的 LLM 训练优化及扩展,为使用 NVIDIA AI 平台训练与部署模型提供新的功能。
全球最大的开放科学、开放取用的多语言模型BLOOM,内有1,760亿个参数,日前在NVIDIA AI平台进行训练,能够产出46个语言及13种编程语言的文字。 NVIDIA AI 平台亦支持其中一个拥有 5,300 亿个参数的强大 Transformer 语言模型,即 Megatron-Turing NLG 模型 (MT-NLG)。
在 LLM 领域的最新进展
LLM 是当今最重要的先进技术之一,模型内有数万亿个参数,可以从文字中进行学习。 但开发 LLM 是个昂贵且耗时的过程,须运用深厚的技术能力、分布式基础设施与完整堆叠才得以完成。
LLM 在推动实时生成内容、文字摘要、客服聊天机器人与通过对话式人工智能(AI)接口的问答等领域,却能带来莫大的好处。 为了推动 LLM 的发展,AI 领域的开发人员不断运用包含 Megatron-LM、Apex 与其他 GPU 加速库的 NVIDIA AI 平台来创新开发工具,像是微软 DeepSpeed、Colossal-AI、Hugging Face BigScience 及 Fairscale。
在 NVIDIA AI 平台推出新的最佳化内容后,能解决整个堆栈中现有的多项痛点。 NVIDIA 期待持续与AI 社群合作,让每个人都能运用 LLM 的强大实力。
缩短 LLM 开发时间
最新的NeMo Megatron更新内容可加快30%的GPT-3模型训练速度,模型从220亿个参数,大至1万亿个参数都可顺利运行。 现在使用1,024个NVIDIAAA100GPU,只要24天就能训练出多达1,750亿个参数的模型,相较于过往版本,训练时间缩短10天,相当于约25万个GPU运算小时。
NeMo Megatron 是一个快速、高效且易用的端到端容器化框架,用于收集数据、训练大型模型、按照业界标准基准评估模型,与以最先进的延迟与传输量表现进行推论。
使用 NeMo Megatron,便能在多种 GPU 群集配置上轻松处理并复制 LLM 的训练和推论作业。 目前抢先体验的客户可以取得这些功能,在 NVIDIA DGX SuperPODs、NVIDIA DGX Foundry 及 Microsoft Azure 云端环境中运行,并且即将开放支持其他云端平台。
目前已开放在 NVIDIA LaunchPad 上体验这些功能。 NVIDIA LaunchPad 是一项免费的计划,提供用户短期内使用 NVIDIA 加速基础设施中的多个实践实验室。
NeMo Megatron 是 NeMo 的一部分。 NeMo 是用于为对话式 AI、语音 AI 和生物学打造高性能与灵活应用程序的开源框架。
两项新技术可加快LLM 的训练速度
更新项目包括两项用于优化及扩展 LLM 训练的新技术,即序列平行 (sequence parallelism; SP) 与选择性激发再运算 (selective activation recomputation; SAR)。
藉由察觉先前未进行平行化的 transformer 层区域在序列维度上是各自独立,序列平行扩大了 tensor 级模型的平行性。
沿着序列维度拆分这些层就能进行分散运算,而最重要的是,这些区域的激发内存分布于tensor平行装置上。 由于以分散方式加以激发,可将更多激发作用保留用于反向运算,而不用重新运算。

图一_transformer层内的平行模式
不同的激发作用需要不同的操作次数来重新运算,选择性激发再运算改善因记忆体限制而部分被迫重新运算,而非全部激发的情况。 除了增加检查点和重新运算整个 transformer 层,亦可建立检查点及重新运算每个 transformer 层中,占用大量内存但重新运算的成本不高的部分。
如需了解更多相关资讯,请见《Reducing Activation Recomputation in Large Transformer Models》。
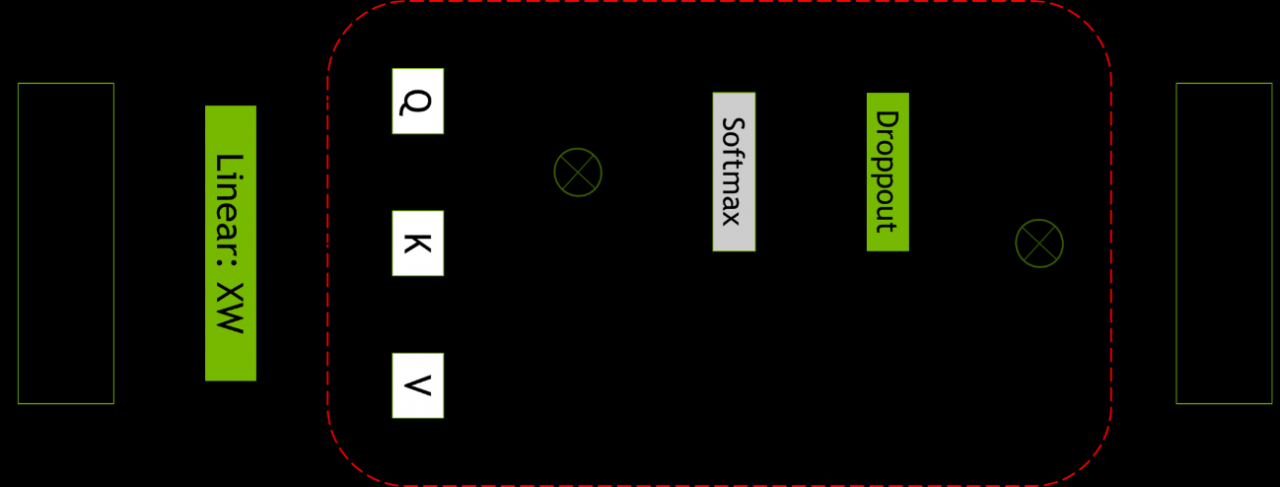
图二_Self-attention 模块。 红色虚线代表应用选择性激发重新运算的区域

图三_SP与 SAR 将激发内存保留用于反向运算。 随着模型大小的增加,SP 与 SAR 皆具类似的内存保留能力,将所需的内存数量减少五倍
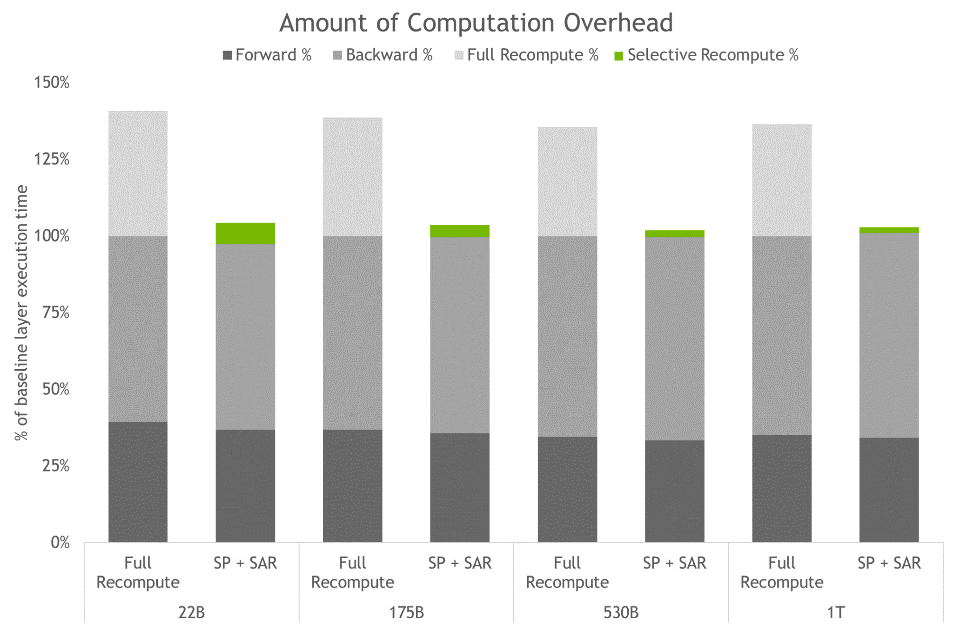
图四:完全激发再运算与SP加上SAR的运算时间。 长条图细分出每层的前向、反向和重新运算时间。 基线是无采用重新运算和序列平行时的情况。 这些技术能在所有激发都被重新运算 (而非保留) 时有效减少额外的运算时间。 最大模型的额外时间从36%降至仅2%
要配合高度优化的推论策略,才能发挥 LLM 的强大实力。 用户可以轻松将训练好的模型用于推论,并且利用 p-tuning 及 prompt tuning 功能对不同的使用情况进行优化调整。
这些功能可以取代微调,让 LLM 可以适应新的使用情况,无需繁琐地对完整预先训练好的模型进行微调。 该技术不会更动原始模型里的参数,便能避免发生因微调模型而出现的灾难性「遗忘」问题。 欲了解更多相关资讯,请见《Adapting P-Tuning to Solve Non-English Downstream Tasks》。
用于训练和推论的全新超参数工具
在分布式基础设施中找出适合 LLM 的模型配置非常耗时。 NeMo Megatron 推出一项超参数工具,可以自动寻找最佳的训练和推论配置,且无需修改代码。 如此一来,LLM 只要一上线便能接受训练以进行推论收敛,不用浪费时间去寻找高效的模型配置。
NeMo Megatron 使用启发式方法和经验网格,在不同参数之间寻找有着最佳传输量的配置:数据平行、tensor 平行、流程平行、序列平行、微批次大小与激发检查点层的数量 (包括选择性激发重新运算)。
在NGC的容器上使用超参数工具与NVIDIA测试,在不到24小时内便替一个有着175B GPT-3模型达到最佳训练配置(请见图五)。 与使用完全激发重新运算的一般配置相比,传输量速度提高20%到30%。 使用最新技术,让具有超过20B参数的模型速度可再加快10%到20%。

图五:将超参数工具用于多个容器上的结果显示,使用序列平行和选择性激发重新运算,有助于加快处理速度,其中每个节点皆搭载英伟达DIA DGX A100
超参数工具亦能找出推论过程中,有着最高传输量或最低延迟的模型配置。 模型可以获得延迟和传输量限制信息,而该工具将会推荐合适的配置。
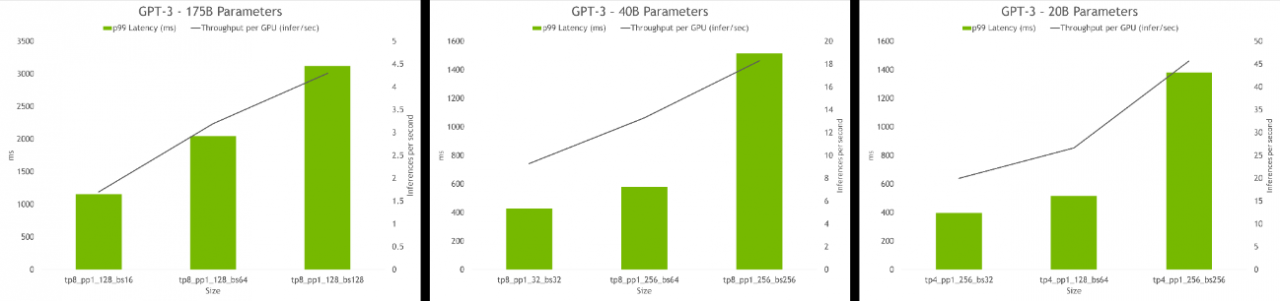
图六_超参数工具的推论结果显示每个 GPU 的传输量及不同配置的延迟情况。 最佳配置包括高传输量及低延迟
欲了解更多关于适用于 LLM 的 NVIDIA AI 平台最新更新内容,敬请申请抢先体验 NeMo Megatron。 企业亦能在 NVIDIA LaunchPad 上免费体验 NeMo Megatron。
 微信扫一扫
微信扫一扫